编写可读代码的艺术 The Art of Readable Code: Simple and Practical Techniques for Writing Better Code
这是一篇编写可读代码的艺术阅读笔记,本文不会讨论项目的架构、设计模式,而是旨在帮助你把基本的代码写得更好。总结了很多提高代码可读性的小技巧,看似都微不足道,但是对于整个软件系统的开发而言,它们与宏观的架构决策、设计思想、指导原则同样重要。编码不仅仅只是一种技术,也是一门艺术,编写可读性高的代码尤其如此。如果你要成为一位优秀的程序员,要想开发出高质量的软件系统,必须从细处着手,做到内外兼修。
关键思想:代码应该写得容易理解
可读性基本定理——代码应当易于理解,其写法应使别人理解它所需的时间最小化。它是衡量代码质量的一个重要标准,且与代码效率、架构等目的不冲突。
我们在写代码的时候,要经常想一想其他人是不是会觉得你的代码容易理解。
第一部分 表面层次的改进
从我们认为的“表面层次”的改进开始:选择好的名字、写好的注释以及把代码整洁的写成更好的格式。这些改变很容易实现。
把信息装到名字里
无论是命名变量、函数还是类,都可以使用很多相同的原则。我们喜欢把名字当做一小小的注释。尽管空间不算很大,但选择一个好名字可以让它承载很多信息。 仅通过读到名字就可以获得大量信息。
- 选择专业的词:避免使用“get”等泛泛的词,根据语境选择更精准的词汇(如“Fetch”“Download”)。
- 找到更有表现力的词:清晰和精确比装可爱好。例如单词 make,更多选择如 create、build、add 等。
- 避免空泛的名字:如“tmp”“retval”,仅在变量短期存在且以临时性为主要特征时使用。
- 用具体的名字代替抽象的名字:命名时把它描述得更具体而不是更抽象,如检测服务是否可以监听某个给定的 TCP/IP 端口的方法“ServerCanStart ()”改为“CanListenOnPort ()”,更清晰描述功能。
- 为名字附带更多信息:对于度量值,添加单位(如“delay_secs”“size_mb”);对于有特殊属性的变量,添加标识(如“unescaped_comment”“html_utf8”)。
- 确定名字长度:作用域小的变量可用短名字,作用域大的变量需包含足够信息;利用编辑器的单词补全功能,不必因输入麻烦而使用过短名字。
- 利用名字的格式传递含义:如类名用“CamelCase”,变量名用“lower_separated”,常量用特定格式等,保持项目内一致性。
不会误解的名字
前面提到如何把信息塞入名字中,在这部分关注另外话题:小心可能会有歧义的名字。 要多问自己几遍:这个名字会被别人解读成其他含义吗?如果会,就需要改名。
- 避免歧义词汇:如“filter”“Clip”等易产生多种解读的词,选择更明确的名字。
- 命名极限:用“max_”“min_”表示包含的极限(如“MAX_ITEMS_IN_CART”)。
- 表示范围:“first”“last”用于包含的范围,“begin”“end”用于包含 / 排除范围。
- 给布尔值命名:使用“is”“has”“can”“should”等词明确含义,最好避免反义名字(如用“use_ssl”代替“disable_ssl”)。
- 与使用者期望匹配:如“get*()”方法通常被认为是轻量级访问器,若其实现复杂,getMean 应改名(如“computeMean ()”),后者听起来更像是有代价的。
审美
整洁的代码更易读,能提高浏览速度。这部分告诉你,如何使用好留白、对齐及顺序让代码更易读。
排版技巧:
- 使用一致的布局,让读者很快就习惯这种风格。
- 让相似的代码看上去相似。
- 把相关的代码行分组,形成代码块。
- 用方法整理不规则代码,减少重复。
- 选择有意义的顺序并保持一致。
- 必要时使用列对齐,使代码更易浏览。
- 把声明和代码按逻辑分组,形成“段落”。
风格一致性:个人风格需服从项目一致性,一致的风格比“正确”的风格更重要。
该写什么样的注释
关键思想:注释的目的是尽量帮助读者了解得和作者一样多。
-
不需要注释的情况:不要为那些从代码本身就能快速推断的事实写注释。不要为了注释而注释。不要给不好的名字加注释——应该把名字改好。
// The class definition for an account. class Account { // ... } // Find the Node in the given subtree, with the given name,using the given depth. function findNodeInSubtree(subtree, name, depth) { // Find the node in the subtree. return subtree.find(n => n.id === node.id); } -
应记录的想法:
- “导演评论”:电影用常有“导演评论”,制作者在其中给出自己见解并通过讲故事帮助你理解。同样你应该在代码中加入注释来记录你对代码有价值的见解。解释代码设计思路、选择原因等。
例如,这段注释教会读者一些事情,并且防止他们为无谓的优化而浪费时间。 - 代码瑕疵:代码始终在演进,并且在这过程中肯定会有瑕疵。不要不好意思把这些瑕疵记录下来。用“TODO:”“FIXME:”“HACK:”“XXX:”等标记。
- 给常量加注释:说明常量值的选择原因。
/** 导演评论 */ // 出乎意料的是,对于这些数据用二叉树比用哈希表快 400% // 哈希运算的代价比左/右比较大得多 /** 给常量加注释 */ NUM_THREADS = 8; // 这一行看上去可能不需要注释,但很可能选择用这个值的程序员知道得比这个要多 // 现在,读代码的人就有了调整这个值的指南了 NUM_THREADS = 8;// as long as it's >= 2 * num_processors, that's good enough. - “导演评论”:电影用常有“导演评论”,制作者在其中给出自己见解并通过讲故事帮助你理解。同样你应该在代码中加入注释来记录你对代码有价值的见解。解释代码设计思路、选择原因等。
-
站在读者角度:本文所用的一个通用技术是,想象你的代码对于外人来讲看起来是什么样子的。
- 预料读者可能困惑的部分并加注释。当别人读你代码的时候,有些部分可能会让他们有这样的想法:“什么?为什么这么写?”,你的工作就是要给这部分加注释。
- 公布可能的陷阱,注释代码的意外行为(如函数的耗时、限制等)。
- 提供“全局观”注释:解释类、文件的作用及各部分如何交互。
- 用注释总结代码块,帮助读者把握整体逻辑。
function generateUserReport(user) { // Acquire a lock for this user // ... // Read the user data from the database // ... // Write the report to the file system // ... // Release the lock }
注释应该说明“做什么”、“为什么”,还是“怎么做”?
你可能听过这样的建议:注释应该说明“为什么这样做”,而非“做什么”或者“怎么做”。这虽然容易记,但是这种说法太简单化了。 我们的建议是,你可以做任何帮助读者更容易理解代码的事。可能包括:做什么、怎么做、为什么的注释。
最后的思考:克服“作者心理阻滞”。很多人不喜欢写注释,是因为写出好的注释要花很多功夫。当你有了这样的担忧,最好的办法就是现在开始写。
请注意我们把写注释这件事拆成了几个简单的步骤:
- 不管你心里想什么,先把它写下来。
- 读一下这段注释,看看有没有什么地方可以改进。
- 不断改进。
写出言简意赅的注释
关键思想:注释应当有很好的信息/空间率。
- 保持紧凑:用简洁的语言传达信息,避免冗余。
- 避免不明确的代词:如“it”“this”可能指代不明时,明确其所指。
// Bad // Insert the data into the cache, but check the data if it's too big first. // Good // Insert the data into the cache, but check the data if the data too big first. - 润色句子:使注释更精确、直接。
// Bad // Depending on whether we've already crawled this URL before, give it a different priority. // Good: 更加简单小巧,且更直接。同时解释了未曾爬到过的 URL 将得到更好优先级 // Give higher priority to URLs we've never crawled before. - 精确描述函数行为:明确函数的输入、输出及处理逻辑。
- 用输入 / 输出例子说明特殊情况:比文字描述更直观。
- 声明代码意图:解释代码的高层次目标,而非表面操作。
// Bad function DisplayProducts(products: Product[]): void { products.sort(CompareProductByPrice); // Iterate through the list in reverse order for (let i = products.length - 1; i >= 0; i--) { DisplayPrice(products[i].price); } } // Good // Display each price, from highest to lowest for (let i = products.length - 1; i >= 0; i--) { DisplayPrice(products[i].price); } - “具名函数参数”的注释:对难以理解的函数参数,用注释说明。
fetchData(/* timeoutMs= */ 5000, /* withCredentials= */ false); function createUser(options: { name: string; isAdmin: boolean; age?: number; }) { // ... } createUser({ name: "Alice", isAdmin: true, });
第二部分 简化循环和逻辑
第一步介绍表面层次的改进,第二部分将进一步介绍程序的”循环和逻辑“:控制流、逻辑表达式,以及让你代码正常运行的那些变量。 通过试试最小化代码中的”思想包袱“来达到目的。
把控制流变得易读
关键思想:把条件、循环以及其他对控制流的改变做得越“自然”越好。运用一种方式使读者不用停下来重读你的代码。
- 比较参数顺序:将变化的值放左边,稳定的值放右边(如“while。
这条指导原则和英语的用法一致。我们会很自然地说:"如果你的年收入至少是 10 万美元"或者"如果你不小于 18 岁。"而"如果 18 岁小于或等于你的年龄"这样的说法却很少见。
if (length>=10) // Good // or if (10 <= length) // Bad while (bytes_received< bytes_expected) // Good // or while (bytes_expected > bytes_received) // Bad - if/else 语句块顺序:先处理正逻辑、简单情况或有趣 / 可疑情况。
// Good if(a==b){ //Case One... }else{ // Case Two... } // Bad if (a!==b){ //Case Two... } else { //Case One... } - 三目运算符:仅在最简单的情况下使用,复杂逻辑用 if/else 更清晰。
相对于追求最小化代码行数,一个更好的度量方法是最小化人们理解它所需的时间。 - 避免 do/while 循环:其条件在代码块后,易造成阅读困惑,可用 while 循环替代。
- 提前返回:减少嵌套,使代码更线性,提高可读性。
function Contains(str: string, substr: string) { if (str == undefined || substr == undefined) { return false; } return str.indexOf(substr) !== -1; } - 最小化嵌套:嵌套过深增加理解难度,可通过提前返回、使用 continue 等减少嵌套。
当你对代码做改动时,从全新的角度审视它,把它作为一个整体来看待。// 嵌套是如何累积而成的 // 最开始代码很简单 if (userResult === SUCCESS) { reply.WriteError("") } else { reply.WriteError(userResult) } replay.Done(); // 后来,另外程序员增加了第二个操作。他找到最合适的地方,新代码很整洁而且这个改动的差异很清晰——看起来是个简单的改动。 if (userResult === SUCCESS) { if (permissionResult !== SUCCESS) { reply.WriteError('error reading permission') replay.Done(); return; } reply.WriteSuccess("") } else { reply.WriteError(userResult) } replay.Done(); // 当后面其他人再看这段代码的时候,所有的上下文不在了。当你读到这段代码,不得不全盘接受它 // 提前返回来减少嵌套 if (userResult === SUCCESS) { reply.WriteSuccess("") } if (permissionResult !== SUCCESS) { reply.WriteError('error reading permission') replay.Done(); return; } reply.WriteError(userResult) replay.Done();
拆分超长的表达式
关键思想:把你的超长表达式拆分成更容易理解的小块。
- 使用解释变量:将长表达式拆分为子表达式,用变量命名说明其含义。
// Bad if (line.split(":")[].strip()=="root") { } // Good username =line.split(":")[0].strip() if (username =="root") { } - 使用总结变量:用短名字代替大段代码,方便管理和思考。
// Bad if (request.user.id === document.owner_id) { // user can edit this document... } if (request.user.id !== document.owner_id) { } // Good const userOwnsDocument = request.user.id === document.owner_id; if (userOwnsDocument) { } - 应用德摩根定理:重写布尔表达式,使其更易读(如“!(a && b)”改为“!a || !b”)。
德摩根定理:分别取反,转换与/或。- 对原布尔表达式中的每个子表达式进行取反操作。例如,对于表达式“非(a 且 b)”,需要分别对“a”和“b”取反,得到“非 a”和“非 b”。
- 将原表达式中的逻辑运算符“与(∧)”转换为“或(∨)”,“或(∨)”转换为“与(∧)”。例如,“非(a 且 b)”中的“且”需转换为“或”,最终等价于“非 a 或 非 b”;而“非(a 或 b)”中的“或”需转换为“且”,等价于“非 a 且 非 b”。
- 避免滥用短路逻辑:复杂的短路逻辑易造成理解困难,可拆分为清晰的语句。
- 拆分巨大语句:将复杂语句拆分为多个部分,提高可读性。
// Bad var update_highlight = function (message_num){ if($("#vote_value"+message_num).html() === "Up") { $("#thumbs_up"+message_num).addClass("highlighted"); $("#thumbs_down"+message_num).removeClass("highlighted"); } else if(("#vote_value"+message_num).html() === "Down"){ $("#thumbs_up"+message_num).removeClass("highlighted"); $("#thumbs_down"+message_num).addClass("highlighted"); } else { $("#thumbs_up"+message_num).removeClass("highlighted"); $("#thumbs_down"+message_num).removeClass("highlighted"); } } // Good var update_highlight = function (message_num){ var vote_value =S("#vote_value"+message_num).html(); var thumbs_up=s("#thumbs_up"+message_num); var thumbs_down =S("#thumbs_down"+ message_num); var hi = "highlighted"; if(vote_value==="Up"){ thumbs_up.addClass(hi); thumbs_down.removeClass(hi); } else if(vote_value==="Down"){ thumbs_up.removeClass(hi); thumbs_down.addClass(hi); } else{ thumbs_up.removeClass(hi); thumbs_down.removeClass(hi); }; }
变量与可读性
草率使用变量会让代码更难理解:变量越多就越难全部跟踪它们的动向。变量的作用域越大,就跟踪它的动向就越久。变量改变越频繁,就越难跟踪它的当前值。
- 减少变量:移除无价值的临时变量、中间结果变量和控制流变量(如通过提前返回消除“done”等控制变量)。
- 缩小变量作用域:让变量对尽可能少的代码行可见,如将类成员变量降为局部变量,利用语言的作用域规则约束变量可见范围。
- 优先使用只写一次的变量:常量或只赋值一次的变量更易理解,减少跟踪其值的难度。
一个综合的例子:假设你有一个网页,上面有几个文本输入字段,布置如下:
<input type="text"id="input1"value="Trevor">
<input type="text"id="input2"value="Hunt">
<input type="text"id="input3"value="">
<input type="text"id="input4"value="Melissa">
如你所见,id 从 input1 开始增加。你的工作是写一个叫 setFirstEmptyInput() 的函数,
它接受一个字符串并把它放在页面上第一个空的<input>字段中 (在给出的示例中是"input3")。这个函数应当返回已更新的那个 DOM 元素 (如果没有剩下任何空字段则返回 null)。
下面是完成这项工作的代码,它没有遵守本章中的原则:
// 定义了 found,i,elem 三个变量,并且多次写入
var setFirstEmptyInput = function (new_value) {
var found = false;
var i = 1;
var elem = document.getElementByd('input'+);
while (elem !==nul1) {
if (elem.value === "") {
found = true;
break;
}
i++;
elem =document.getElementByd('input'+i);
}
if (found) {
elem.value = new_value;
}
return found ? elem : null;
}
// 改进:移除 found 变量,提前返回
var setFirstEmptyInput = function (new_value) {
var i = 1;
var elem = document.getElementByd('input'+i);
while (elem !==nul1) {
if (elem.value === "") {
elem.value = new_value;
return;
}
i++;
elem = document.getElementByd('input'+i);
}
return null;
}
// 继续改进:elem 在代码中多次用到,很难追踪,改成 for 循环
var setFirstEmptyInput = function (new_value) {
for (let i = 1; true; i++) {
elem = document.getElementByd('input'+i);
if (elem === null) {
return null;
}
if (elem.value === "") {
elem.value = new_value;
return elem;
}
}
}第三部分 重新组织代码
这部分讨论在函数级别对代码做更大的改动。具体来说包括三种组织代码的方法:
- 抽取出那些与程序主要目的“不相关的子问题“
- 重新组织代码使它一次制作一件事
- 先用自然语言描述代码。然后用这个描述来帮助你找到更简洁的解决方案。
抽取不相关的子问题
所谓的工程学就是关于把大问题拆解成小问题再把这些小问题的解决方案放回一起。把这条原则应用于 代码会是的代码更健壮并且更容易读。
- 核心思想:将代码中解决不相关子问题的部分抽取为独立函数,使主代码更专注于高层次目标。
- 看看某个函数或代码块,问问你自己:这段代码高层次的目标是什么?
- 对于每一行代码问一下,它直接为了目标而工作吗?
- 如果足够的行数在解决不相关的子问题,抽取代码到独立的函数中。
- 适用场景:
- 纯工具代码:如文件操作、字符串处理等通用功能。
- 多用途代码:如格式化输出、数据加密等可在多处复用的功能。
- 简化已有接口:为复杂接口创建包装函数,隐藏细节。
例如你需要处理 JavaScript 浏览器中的 cookie,从概念上讲 cookie 是一个键值对,但浏览器只提供一个 document.cookie 的字符串,你需要解析这个字符串来获取你需要的 cookie 值。 这个时候你可以创建一个getCookie()函数,它接受一个 cookie 名称作为参数,返回对应的值。
- 注意事项:避免过度拆分,抽取的函数应能真正提高可读性和复用性。
总结来说“把一般代码和项目转悠代码分开”,其结果是,大部分代码都是一般代码。通过建立一个库和辅助函数来解决一般问题。剩下的只是让你程序与众不同的部分。
这个技巧有帮助的原因是它使程序员关注小而定义良好的问题,这些问题已经同项目的 其他部分脱离。其结果是,对于这些子问题的解决方案倾向于更加完整和正确。你也可以在以后重用它们。
一次只做一件事
- 关键思想:将代码组织成一次只处理一个任务,可拆分为不同函数或同一函数中的不同段落。
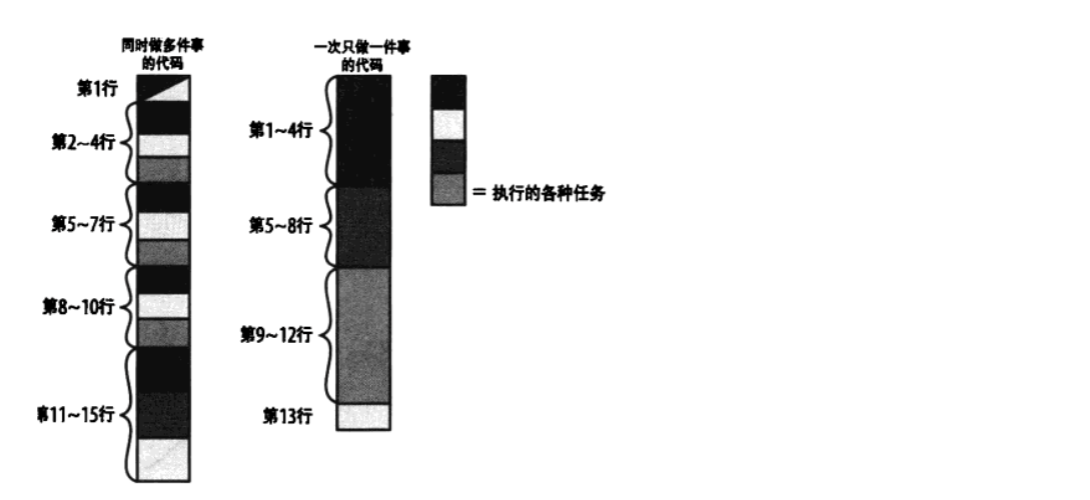
- 步骤:
- 列出代码所做的所有任务。这里任务没有严格定义。
- 尽量将任务拆分到不同函数,至少是代码中不同的段落中。
- 好处:使代码逻辑清晰,各任务的开始和结束更明确,便于理解和维护。
把想法变成代码
当把一件复杂的事情想别人解释时,哪些小的细节很容易让他们迷惑。 把一个想法用“自然语言”解释是一个很有价值的能力,因为这样其他人也能理解它。这需要把一个想法精炼成最重要的概念。 这样不仅帮助他人理解,而且也能帮助你把这个想法想得更清楚。
- 过程:
- 用自然语言向同事描述代码要做的事。
- 关注描述中的关键词和短语。
- 写出与描述匹配的代码。
- 好处:使代码更贴合逻辑,易于理解;帮助发现可拆分的子问题,优化代码结构。
少写代码
知道什么时候不写代码可能对于一个程序员来讲是他所要学习的最重要的技巧。你所写的每一行代码都是要测试和维护的。 通过重用库或者减少功能,你可以节省时间并且让你的代码库保持精简节约。
- 避免不必要的功能:程序员常高估功能的必要性,很多功能可能未被使用或增加程序复杂度。
- 质疑和拆分需求:简化问题,解决最基本的需求即可。例如你需要实现一个商店定位功能,即对于任何用户找到距离最近的商店。如果 100% 实现需要考虑当位置处于 日期分界线的情况、接近南北极情况、地球表面曲度。但是如果你只有在加州的 30 店,那这些问题就不重要,需求变为“为加州附近的用户,找到最近的店铺”
- 保持小代码库:通过创建工具代码减少重复、删除无用代码、将项目拆分为子项目等,使代码库更轻量。
- 熟悉库函数:充分利用标准库和现有库,避免重复开发,定期阅读库的 API 文档以了解可用功能。
第四部分 精选话题
本书前三部分覆盖了使代码简单易读的各种技巧。在该部分中,我们会把这些技术应用在两个精选出的话题中。
测试与可读性
关键思想:测试应当具有可读性,以便其他程序员可以舒服地改变或者增加测试。
- 测试代码的重要性:测试代码的可读性同样重要,可作为非正式文档,帮助理解真实代码的行为和使用方式。
- 改进测试的技巧
- 每个测试的最高一层应该越简明越好。最好每个测试的输入输出可以用一行代码来描述。
- 如果测试失败了,它所发出的错误消息应该能让你容易跟踪并修正这个 bug。
- 使用最简单的并且能够完整运用代码的测试输入。
- 给测试函数取一个有完整描述性的名字,以使每个测试所测到的东西很明确。不要用
Test1(),而用像Test_<FunctionName><Situation>这样的名字。
- 可测试性差的代码的特征,以及它所带来的设计问题
| 特征 | 可测性的问题 | 设计问题 |
|---|---|---|
| 使用全局变量 | 对于每个测试都要重置所有全局状态,否则不同的测试之间会互相影响 | 很难理解哪些函数有什么副作用。没办法独立考虑每个函数,要考虑整个程序才能理解是不是所有的代码都能工作 |
| 对外部组件有大量依赖的代码 | 很难给它写出任何测试,因 为要先搭起太多的脚手架。写测试会比效无趣,因此人 们会避免写测试 | 系统会更可能因某一依赖失败而失败。对于改动来讲很难知道会产生什么样的影响。很难重构类。系统会有更多的失败模式,并且要考虑更多恢复路径 |
| 代码有不确定的行为 | 测试会很古怪,而且不可靠。经常失败的测试最终会被忽略 | 这种程序更可能会有条件竞争或者其他难以重现的 bug。这种程序很难推理。产品中的 bug 很难跟踪和改正 |
- 可测试性较好的代码的特征,以及它所产生的优秀设计
| 特征 | 对可测性的好处 | 对设计的好处 |
|---|---|---|
| 类中只有很少或者没有内部状态 | 很容易写出测试,因为要测试一个方法只要较少的设置,并且有较少的隐藏状态需要检查 | 有较少状态的类更简单,更容易理解 |
| 类/函数只做一件事 | 要测试它只需要较少的测试 | 较小/较简单的组件更加模块化,并且一般来讲系统有更少的耦合 |
| 每个类对别的类的依赖很少,低耦合 | 每个类可以独立地测试 (比多个类一起测试容易得多) | 系统可以并行开发。可以很容易修改或者删除类,而不会影响系统的其他部分 |
| 函数的接口简单,定义明确 | 有明确的行为可以测试。测试简单接口所需的工作量较少 | 接口更容易让程序员学习,并且重用的可能性更大 |
设计并改进“分钟 / 小时计数器”
通过一个例子,一起看看一个工程师可能会经历的自然思考过程:首先试着解决问题、然后改进它的性能和增加功能 最重要的是,就用前面的原则试着让代码保持易读。
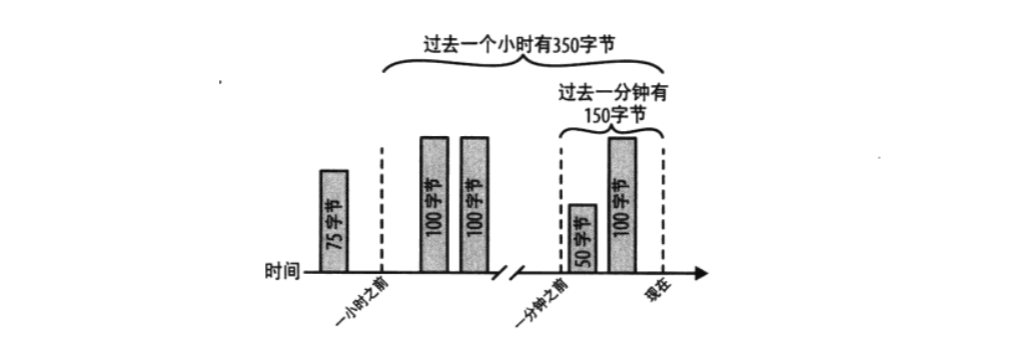
问题
我们需要跟踪在过去的一分钟和一个小时里 Web 服务器传输了多少字节。下面的图示说明了如何维护这些总和:
定义类接口
interface MinuteHourCounter {
// Add a count
counter(numBytes: number): void;
// Return the count over this minute
minuteCount(): number;
// Return the count over this hour
hourCount(): number;
}改进命名
类名是比价好的,方法名 minuteCount 和 hourCount 也比较好。你可能会给它们起 getMinuteCount 和 getHourCount。
但这样没有帮助。因为”get“暗示着”轻量级的访问器“,但是实现并不会是轻量的。
但是 counter 这个方法有问题,有的人可能认为它的意思是”返回所有时间里的总的计数“。它既是动词也是名词。既可以是"我想要得到你所见过的所有样本的计数"的意思也可以 是"我想要你对样本进行计数"的意思。
所以这里可以改为:add。
另外这里的 numBytes 太有针对性了。确实主要的用例是对字节计数,但是 MinuteHourCounter 没必要知道这一点。
所以改为 count。
改进注释
interface MinuteHourCounter {
// Add a count
add(count: number): void;
// Return the count over this minute
minuteCount(): number;
// Return the count over this hour
hourCount(): number;
}再看一遍注释并改进它。
//Add a count
void Add(int count);这条注释完全多余——要么删除它要么改进它。
再看看 minuteCount 方法的注释。当我们问同事这段注释的含义时,可能得到两种冲突的解读:
- 返回当前所在的时间(例如 12:12 pm)所在的分钟中的计数。
- 返回过去 60s 内的计数,和时钟边界无关。 第二种才是它的工作方式,所以我们把这个混淆用更明确和具体的语言解释清楚。
最后还有一条类的注释。
// Track the cumulative counts over the past minute and over the past hour.
// Useful,for example,to track recent bandwidth usage.
interface MinuteHourCounter {
// Add a new data point
// For the next minute, minuteCount() will be larger by +count.
// For the next hour, hourCount() will be larger by +count.
add(count: number): void;
// Return the accumulated count over the past 60 seconds
minuteCount(): number;
// Return the accumulated count over the past 3600 seconds
hourCount(): number;
}你已经注意到,我们可以通过同事来帮助我们解决问题,询问外部视角的观点是你测试你的代码是否“对用户”友好的好办法。
尝试一:一个幼稚的方式
开始解决这个问题,我们会从一个很直接的方式开始:就是保持一个有时间戳的事件列表
interface Event {
timestamp: number;
count: number;
}
class BytesMinuteHourCounter implements MinuteHourCounter {
private events: Event[] = [];
add(count: number): void {
this.events.push({
time: Date.now(),
count,
});
}
minuteCount(): number {
let count = 0;
const nowSecs = Date.now();
for (let i = this.events.length - 1; i >= 0; i--) {
if (this.events[i].time > nowSecs - 60 * 1000) {
count += this.events[i].count;
} else {
break;
}
}
return count;
}
hourCount(): number {
let count = 0;
const nowSecs = Date.now();
for (let i = this.events.length - 1; i >= 0; i--) {
if (this.events[i].time > nowSecs - 60 * 60 * 1000) {
count += this.events[i].count;
} else {
break;
}
}
return count;
}
}这段代码易于理解吗
- for 循环太大了,一口吃不下
- minuteCount 和 hourCount 方法的逻辑是一样的,代码重复。可以通过提取公共逻辑来改进。
一个更易读的版本
class BytesMinuteHourCounter implements MinuteHourCounter {
private events: Event[] = [];
countSince(time: number): number {
let count = 0;
// 用 rit 表示反向迭代器
for (let rit = this.events.length - 1; rit >= 0; rit--) {
if (this.events[rit].time > time) {
count += this.events[rit].count;
} else {
break;
}
}
return count;
}
add(count: number): void {
this.events.push({
time: Date.now(),
count,
});
}
minuteCount(): number {
return this.countSince(Date.now() - 60 * 1000);
}
hourCount(): number {
return this.countSince(Date.now() - 60 * 60 * 1000);
}
}性能问题
这个设计有两个严重的性能问题
- 它一直不停增大:这个类保存它见过的所有事件,会导致内存使用量无限增长。最好能自动删除超过一个小时的事件,因为不需要了。
- minuteCount 和 hourCount 性能太慢:countSince 方法事件复杂度
O(0),每次都需要遍历所有事件。最好 MinuteHourCounter 能记住 minuteCount 和 hourCount 的值,并随 add 方法调用而更新。
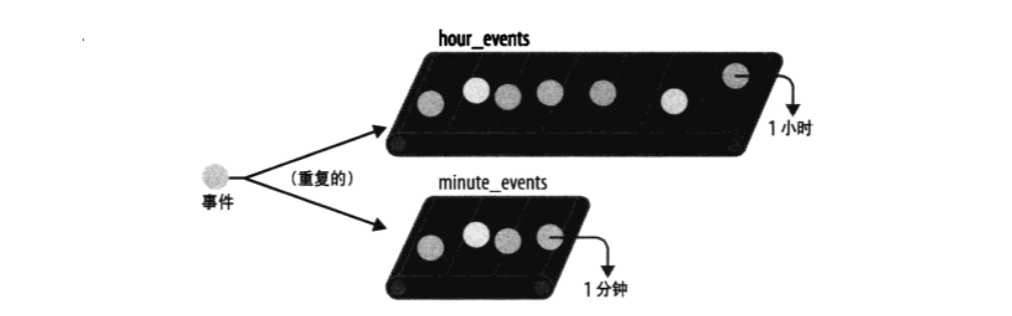
尝试 2:传送带设计方案
打算这样做:我们会像传送带一样使用 list,当数据在一端到达,就会在总数上增加。当数据太旧,就从另一端“掉落”,并从总数中减去。
- 维护两个独立 list:
- 维护两个 list,事件先进入第一个再进入第二个:
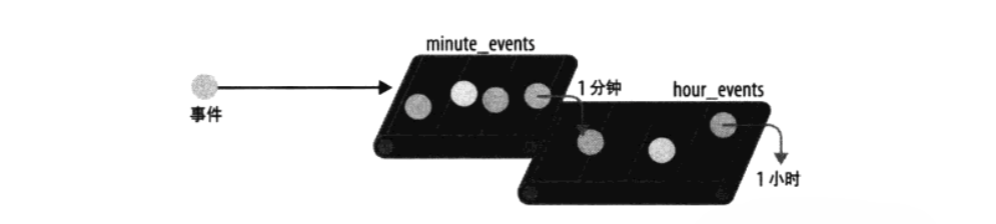
我们会采用“两阶段”这会走功能方式,看上去更有效。
class BytesMinuteHourCounter implements MinuteHourCounter {
private minuteEvents: Event[] = [];
private hourEvents: Event[] = [];
private minuteCount: number = 0;
private hourCount: number = 0;
add(count: number): void {
const nowSecs = Date.now();
shiftOldEvent(nowSecs);
// Feed into the minute list (not into the hour list, that will happen later)
this.minuteEvents.push({
time: nowSecs,
count,
});
// Update the minute count
this.minuteCount += count;
// Update the hour count
this.hourCount += count;
}
minuteCount(): number {
shiftOldEvent(Date.now());
return this.minuteCount;
}
hourCount(): number {
shiftOldEvent(Date.now());
return this.hourCount;
}
// Find and delete old events. and decrease minuteCount and hourCount
shiftOldEvent(nowSecs: number): void {
const minuteAgo = nowSecs - 60 * 1000;
const hourAgo = nowSecs - 60 * 60 * 1000;
// Move events more than one minute old from 'minute_events' into 'hour_events'
// (Events older than one hour will be removed in the second loop.)
while (this.minuteEvents.length > 0 && this.minuteEvents[0].time <= minuteAgo) {
this.hourEvents.push(this.minuteEvents[0]);
this.minuteCount -= this.minuteEvents[0].count;
this.minuteEvents.shift();
}
// Remove events more than one hour old from 'hour_events'
while (this.hourEvents.length > 0 && this.hourEvents[0].time <= hourAgo) {
this.hourCount -= this.hourEvents[0].count;
this.hourEvents.shift();
}
}
}这样就完成了吗
对很多应用来说已经足够了,但是还有缺点:
- 首先设计不灵活,如果期望保留 24 小时计数,可能要大改代码。shiftOldEvent 是一个很集中的函数,在分钟与小时之间做了微妙的互动。
- 其次,这个类占用内存不小。假设是一个高流量的服务,因为我们需要保存过去一个小时的事件,可能用到 5MB 内存。add 调用越多内存就越大。
尝试 3: 时间桶设计
这里关键思想是:把一个小时窗之内的事件装到桶里,然后用一个总和累加这些事件。 例如,过去 1 分钟的事件可以插入 60 个离散桶里,每个有一秒钟宽。过去一个小时也可以插入 60 个离散桶里,每个有 1 分钟宽。
这些方法精度会是 1/60。如果要更精确可以使用更多桶,以使用更多内存为交换。
实现桶设计
如果只用一个类来设计会有很多错综复杂的代码,所以我们创建一些不同类来处理不同问题。
class TrailingBucketCounter {
// Example: trailingBuckerCounter(30, 60) tracks the last 30 minute-buckets of time.
trailingBuckerCounter(numBuckets: number, secsPerBucket: number) {
}
add(count: number, now: number): void {
}
// Return the total cover the last numBuckets worth of time
trailingCount(now: number): number {
}
}
class BytesMinuteHourCounter implements MinuteHourCounter {
class MinuteHourCounter {
private minuteCounts: TrailingBucketCounter;
private hourCounts: TrailingBucketCounter;
constructor() {
this.minuteCounts = new TrailingBucketCounterImpl(/*numBuckets*/60, /*secsPerBucket*/1);
this.hourCounts = new TrailingBucketCounterImpl(/*numBuckets*/60, /*secsPerBucket*/60);
}
add(count: number): void {
const now = Date.now();
this.minuteCounts.add(count, now);
this.hourCounts.add(count, now);
}
minuteCount(): number {
const now = Date.now();
return this.minuteCounts.trailingCount(now);
}
hourCount(): number {
const now = Date.now();
return this.hourCounts.trailingCount(now);
}
}这段代码可读性更强,也更灵活。
实现了 TrailingBucketCounter 类
再一次,创建一个辅助类来进一步拆分这个问题:一个叫做 ConveyorQueue 的数据结构,它的工作是处理其下的计数与总和。
TrailingBucketCounter 类可以只关注过去了多少时间来移动 ConveyorQueue。
ConveyorQueue 接口:
// A queue with a maximum number of slots, where old data "falls off" the end.
interface ConveyorQueue {
// Increment the value at the back of the queue.
addToBack(count: number): void;
// Each value in the queue is shifted forward by 'num_shifted'.
// New items are initialized to 0.
// Oldest items will be removed so there are <= max_items.
shift(num_shifted: number): void;
// Return the total value of all items currently in the queue.
totalSum(): number;
}
class TrailingBucketCounter {
private buckets: ConveyorQueue;
private secsPerBucket: number;
private lastUpdateTime: number; // the last time Update() was called
constructor(numBuckets: number, secsPerBucket: number) {
this.buckets = new ConveyorQueueImpl(numBuckets);
this.secsPerBucket = secsPerBucket;
this.lastUpdateTime = Date.now() / 1000;
}
// Calculate how many buckets of time have passed and shift accordingly.
private update(now: number): void {
const currentBucket = Math.floor(now / (this.secsPerBucket));
const lastUpdateBucket = Math.floor(this.lastUpdateTime / (this.secsPerBucket));
const bucketShift = currentBucket - lastUpdateBucket;
this.buckets.shift(bucketShift);
this.lastUpdateTime = now;
}
add(count: number, now: number): void {
this.update(now);
this.buckets.addToBack(count);
}
trailingCount(now: number): number {
this.update(now);
return this.buckets.totalSum();
}
}继续实现 ConveyorQueue 类:
class ConveyorQueueImpl implements ConveyorQueue {
private queue: number[] = [];
private maxItems: number;
private totalSum: number = 0;
constructor(maxItems: number) {
this.maxItems = maxItems;
}
addToBack(count: number): void {
if (this.queue.length === 0) {
// Make sure queue has at least one item.
this.shift(1);
}
this.queue[this.queue.length - 1] += count;
this.totalSum += count;
}
shift(numShifted: number): void {
// In case too many items shifted, just clear the queue.
if (numShifted >= this.maxItems) {
this.queue = [];
this.totalSum = 0;
return;
}
// Push all the needed zeros.
while (numShifted > 0) {
this.queue.push(0);
numShifted--;
}
// Let all the excess items fall off.
while (this.queue.length > this.maxItems) {
this.totalSum -= this.queue[0];
this.queue.shift();
}
}
totalSum(): number {
return this.totalSum;
}
}